Floatp Stack: Ett litet sommarhack
Sommaren 2022 hade jag en vecka för mig själv hemma och visste inte vad jag skulle programmera för något. Det blev en liten stackmaskin med tjugotre instruktioner skriven i C och en assemblerare skriven i Emacs Lisp. Det var trevlig förströelse att bekanta sig med ncurses och prova att skriva ett FORTH-inspirerat system i assembler för en påhittad dator.
Virtuell maskin
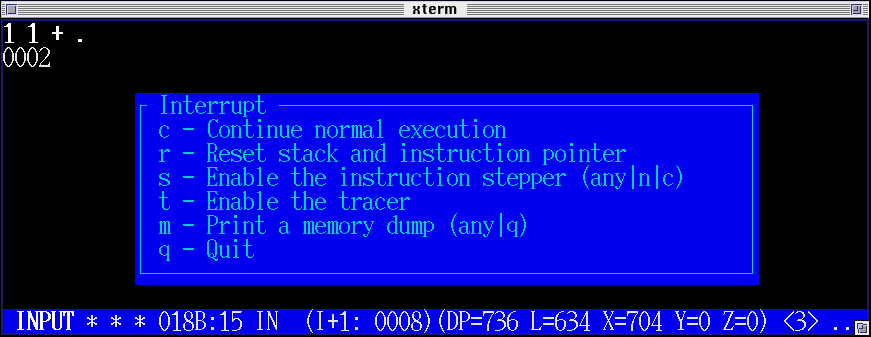
Skärmdumpen ovan visar hur monitorns dialogruta ser ut. När man startar maskinen anger man filnamnet för den HEX-fil som skall laddas i minnet, stack-storlek, minnes-storlek och adress till reset-vektorn. Dessutom kan man namnge särskilda platser i minnet som sedan visas i status-raden längst ner, ungefär som mode-line i Emacs, vilket är praktiskt om vissa platser i minnet fungerar som register i ens program. Se DP, L, X, Y, Z i skärmdumpen för exempel.
Usage: vm image stack-size memory-size reset-vector { -r<REGISTER>=<ADDRESS> }
Det är en piss-enkel maskin, utrustad med allmänt minne och särskilt minne för stacken. Den har ett register för instruktionspekaren, och ett register för en pekare till returstacken, som huserar i det allmänna minnet. Stacken består av ett särskilt register för det översta objektet och en pekare till resten av stacken i stack-minnet.
typedef short int word; // memory word m_size; word* m; // instruction pointer word i; // return stack pointer word r; // stack word s_size; word* s; word* nos; word tos;
När maskinen kör nöter den runt, runt i en switch-sats tills dess att HLT exekveras. Om monitorn inkluderades vid bygget av maskinen signalerar instruktionerna HLT och BRK signalen SIGINT, vilket får effekten att monitor-dialogen visas.
int branch = 0; while (1) { #ifdef __MONITOR_H mon_next(); #endif switch(m[i++]) { [...] case PH: *++nos = tos; tos = m[i++]; [...] case JSR: m[--r] = i + 1; i = m[i]; [...] case BEQ: branch = ! tos; goto MAYBE_BRANCH; [...] } continue; MAYBE_BRANCH: if (branch) { i += m[i]; } else { i++; } tos = *nos--; }
Instruktioner
Maskinen stödjer endast omedelbar addressering, vilket innebär att förhållandet mellan opcode och mnemonic är 1:1. Det hade kanske underlättat programmeringen om maskinen haft stöd för indexerad adressering också, men jag tycker nog att instruktionssetet är lite onödigt stort som det är.
| HLT | Halt: exit or raise SIGINT when monitor is present | |
| BRK | Break: NOP or raise SIGINT when monitor is present | |
| PH | word | Push to stack |
| PL | Pull from stack | |
| LD | Load from memory | |
| ST | Store to memory | |
| LDR | Load current return address and push to stack | |
| STR | Pull from stack and store as current return address | |
| JSR | address | Jump to subroutine |
| RTS | Return from subroutine | |
| BEQ | offset | Pull from stack and branch on zero |
| BNE | offset | Pull from stack and branch on not zero |
| BMI | offset | Pull from stack and branch on negative |
| AND | Boolean AND ( nos tos – x ) | |
| OR | Boolean OR ( nos tos – x ) | |
| XOR | Boolean XOR ( nos tos – x ) | |
| ASL | Arithmetic Shift Left ( tos – x ) | |
| LSR | Logical Shift Right (tos – x ) | |
| SUB | Subtract ( x y – z ) | |
| MUL | Multiply ( x y – z ) | |
| DIV | Divide ( x y – z ) | |
| IN | Read a character from standard input and push to stack | |
| OUT | Pull a character from stack and write to standard output |
Utöver maskinens instruktioner har assembleraren två pseudo-instruktioner. De känns igen från andra assemblerare.
| ORG | address | Set origin (assembler program counter) |
| DATA | { word } | Inline any sequence of words |
Assemblerare
Assembleraren är skriven i Emacs Lisp. Man skriver sitt program i en buffert och kör kommandot `floatp-asm-to-directory' ("space t a" med praktiska floatp-modal-mode) och då skrivs en HEX-fil ut med själva programmet, samt en C-header som definerar opcode per mnemonic samt en array med mnemonics för monitorn att använda vid utskrifter. C-headern används när maskinen kompileras och HEX-filen ges som argument till maskinen när den startas.
#define VERSION 1 // Opcodes #define HLT 0 #define BRK 1 [...] #ifdef __MONITOR_H // Mnemonics char* mnemonics[] = { "HLT", "BRK", [...]
HEX-filer från assembleraren ser ut såhär. Den börjar med ett versions-nummer som måste överensstämma med med versions-numret i C-headern. En rad som börjar med punkt styr inläsningens programräknare och härstammar från ORG-direktiv i assemblerkoden. Resten är maskin-ord som skrivs till minnet.
V0001 .0000 02E0 027A 0000 0000 0000 .0020 0008 02BD 0000 0002 0002 0004 0009 0002 0002 0005 0009 0002 0002 0004 0002 FFFF 0012 0002 0002 0005 0009 0002 0003 0004 0009 0002 0003 0005 0009 0002 0003 0004 0002 FFFF 0012 0002 0003 0005 0009 0002 0004 0004 0009 0002 0004 0005 0009 0002 0004 0004 0002 FFFF 0012 0002 0004 0005 0009 0002 0004 0004 0002 0001 0012 0002 [...]
Jag nämnde lite tidigare att mitt projekt bland annat gick ut på att prova att skriva ett FORTH-inspirerat system för den här maskinen. Jag har inte hittat på något nytt och det är inte komplett eller ens användbart. Likt andra FORTH så provar jag att skriva FORTH i FORTH, och ordlistan har en klassisk uppbyggnad i form av en länkad lista.
I skärmdumpen längst upp på sidan tolkas "1 1 + ." och tolken ger svaret "0002", infix-notation skrivs det såhär: "1+1=2". För att ta reda på vad "1 1 + ." betyder behöver tolken prova, ord för ord, om ordet finns i ordlistan eller om ordet är ett heltal. Ord som återfinns i ordlistan exekveras och heltal läggs på stacken. Ordet "+" tar de två översta orden från stacken, adderar dessa och lägger tillbaka resultatet. Ordet "." tar det översta ordet från stacken, omvandlar detta till textrepresentation och skriver ut resultatet.
I kodsnutten nedan visas ett exempel på ett ord i ordlistan "+", alltså addition. Eftersom ingen instruktion för addition finns används invertering och subtraktion för att addera talen.
symbol_add: DATA "+" ; Ordets symbol DATA (- div 2) ; Adressen för nästa ord i ordlistan DATA @symbol_add ; Adressen för ordets symbol add: ; ( x y -- x+y ) PH 0 JSR @swap SUB SUB RTS
Här är ytterligare ett exempel från samma program. Det är kodfältet för det ord som söker efter ett ord i den länkade listan tills antingen ordet påträffas eller sökningen nått listans slut.
search: ; ( symbol-address -- word-address true | false ) JSR @l ; start searching at l search_r: LD ; ( symbol-address word-address ) 0 = end of dictionary JSR @dup BEQ +search_failed ; reached the end of the dictionary JSR @dup PH -1 ; 1+ is the offset to a word's symbol address SUB LD ; ( symbol-address word-address word-symbol-address ) JSR @pick ; ( symbol-address word-address word-symbol-address symbol-address ) JSR @string_equal ; ( symbol-address word-address boolean ) BEQ +search_succeeded PH 0 BEQ +search_r search_succeeded: ; ( symbol-address word-address ) JSR @swap PL PH 0 RTS search_failed: ; ( symbol-address word-address ) PL PL PH -1 RTS
Klart slut
Det var ett kul projekt så länge det varade. Om jag skulle ta upp det igen skulle det nog vara för att krympa instruktionssetet eller skriva vidare på FORTH-systemet, vi får väl se om det någonsin blir verklighet …